Reference
- 문제 출처 - HackerRank
- 파이썬 연습 - Practice - Python
개인적인 생각과 상상으로 작성한 내용들이 포함되어 있습니다
문제를 풀고 Discussion Tab을 참고하며 코드 스타일을 개선하려고 노력하고자 합니다
HackerRank
HackerRank의 Python 연습문제들은 아래와 같은 카테고리로 분류 된다:
Subdomain
IntroductionBasic Data Types- Strings
- Sets
- Math
- Itertools
- Collections
- Date and Time
- Errors and Exceptions
- Classes
- Built-Ins
- Python Functionals
- Regex and Parsing
- XML
- Closures and Decorators
- Numpy
- Debugging
Strings
기본 개념
Capitalize!
문제 : 사람 이름의 첫 문자를 대문자로 바꾸는 문제
chris alan
Chris Alan
os 패키지는 표준 라이브러리를 다루면서 한번 정리할 예정
def solve(s): |
The Minion Game
문제 : 문자열 S를 입력받으면 두 사람(Stuart, Kevin) 각각 자음(consonant), 모음(vowel)으로 시작하는 단어 조합의 총 개수를 비교하여 큰 사람의 이름과 그 숫자를 출력하는 문제
예제 : ‘BANANA’에서 ‘ANA’는 2번 나타나기 때문에 score는 2가 된다. 아래 그림을 참고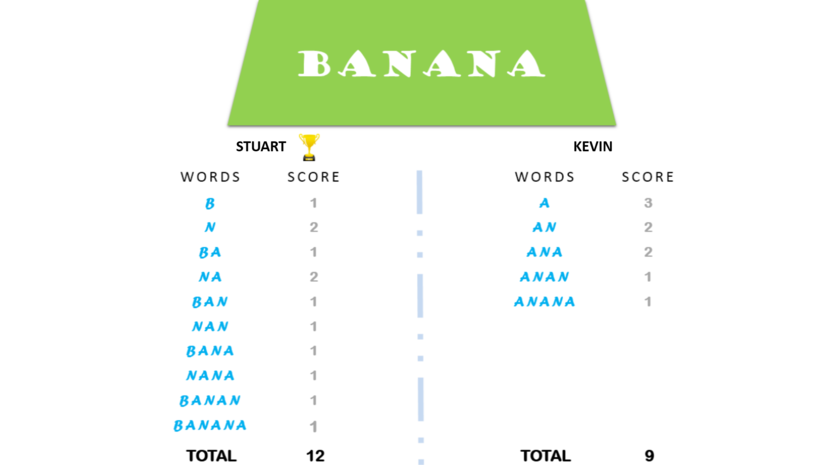
BANANA
Stuart 12
def minion_game(string): |
Several optimizations.
Use frozenset for the vowels. This is the fastest to lookup in.
Iterate through characters instead of indexing
Iterate q reverse to avoid a subtraction in each sum
Avoid repeated calls to len
Only calculate Kevins score the hard way. Use the fact that the total number of substrings is n * (n + 1) / 2 and find Stuart’s score by subtracting Kevin’s from the total number of substrings.
def minion_game(s):
V = frozenset("AEIOU")
n = len(s)
ksc = sum(q for c, q in zip(s, range(n, 0, -1)) if c in V)
ssc = n \* (n + 1) // 2 - ksc
if ksc > ssc:
print("Kevin {:d}".format(ksc))
elif ssc > ksc:
print("Stuart {:d}".format(ssc))
else:
print("Draw")
Merge the Tools!
입력 : 문자열 s와 정수 k를 입력받는다(k는 문자열 길이(n)의 약수)
출력 : k의 배수에 위치한 문자를 기준으로 sub-문자열을 구분하고 반복되는 문자는 삭제해서 출력
예제 : 문자열 ‘AABCAAADA’에서 길이 3으로 자르면 ‘AAB’ ‘CAA’ ‘ADA’ 3개의 sub-문자열로 나뉘고 여기서 중복되는 문자를 제거하면 ‘AB’ ‘CA’ ‘AD’가 된다
AABCAAADA
3
AB
CA
AD
문제의 조건을 직접 충실히 확인하는 기초적인 방법
def merge_the_tools(string, k): |
main 함수일 때 실행한다는 코드는 생략
textwrap은 지난 문제에서 다뤘지만 OrderedDict 패키지는 처음봤지만 이런 방법도 있다
from collections import OrderedDict
import textwrap
def merge_the_tools(string, k):
b=textwrap.wrap(string,k)
for i in range (len(b)):
print("".join(OrderedDict.fromkeys(b[i])))가장 인기가 높은 해답
Discussion forum 참고!
S, N = input(), int(input())
for part in zip(_[iter(S)] _ N):
d = dict()
print(''.join([ d.setdefault(c, c) for c in part if c not in d ]))